인프런 커뮤니티 질문&답변
작성한 질문수

Retention 쿼리를 작성하면서.. 궁금한점이 있습니다.
해결된 질문
작성
·
104
0
Weekly Retention은 diff_of_week 을 활용하여, 시간의 경과에 따른 리텐션 변화를 구합니다. 따라서, 제가 생각했을 때, Weekly Retention을 구하는 쿼리에서는 다음과 같은 가정을 하고 진행한 것이 아닐까? 라는 생각이 들었습니다.
주차별로(시간에 따라) 활동 중인 사용자 수는 달라질 것이다.
user_type에 따라 활동 중인 사용자 수는 차이가 있을 것이다.
2.의 경우는 만약의 신규/복귀... 유저를 구분한다면, 해당 가설을 기반으로, Weekly Retention을 구하는 행위를 한 것이 아닐까? 라는 생각이 들었습니다.
(추가 궁금증)
Retention에 영향을 주는 인자를 분석하는 경우도 있을까요? (실무에서)
저는 Retention을 분석하기 전에, Retention과 관련이 높은 것이 무엇일지, 가설을 세우고 검정을 해보았습니다.
가설: 방문일수는 Retention에 높은 상관관계를 가진다.
데이터 범위: 2022-08-01 ~ 2022-11-01
D7_retention: (bool) 사용자의 첫번째 이벤트 시점 ~ 7일 이후에도 활동을 하면, 1 아니면 0D30_retention: (bool) 사용자의 첫번째 이벤트 시점 ~ 30일 이후에도 활동을 하면, 1아니면 0
import os
from google.cloud import bigquery
from google.oauth2 import service_account
import pandas as pd
import statsmodels.api as sm
from scipy.stats import pointbiserialr
import numpy as npos.environ['GOOGLE_APPLICATION_CREDENTIALS'] = './service_account.json'
key_path = './service_account.json'
credentials = service_account.Credentials.from_service_account_file(
key_path,
scopes = ["https://www.googleapis.com/auth/cloud-platform"],
)
client = bigquery.Client(credentials=credentials,
project=credentials.project_id,
location="US")query = """
WITH user_visits AS (
SELECT
user_pseudo_id,
COUNT(DISTINCT event_date) AS visit_days
FROM
advanced.app_logs
WHERE
event_date BETWEEN '2022-08-01' AND '2022-11-01'
GROUP BY
user_pseudo_id
),
retention_data AS (
SELECT
user_pseudo_id,
MIN(event_date) AS first_event_date,
MAX(event_date) AS last_event_date,
CASE
WHEN MAX(event_date) >= DATE_ADD(MIN(event_date), INTERVAL 7 DAY) THEN 1
ELSE 0
END AS D7_retention,
CASE
WHEN MAX(event_date) >= DATE_ADD(MIN(event_date), INTERVAL 30 DAY) THEN 1
ELSE 0
END AS D30_retention
FROM
advanced.app_logs
WHERE
event_date BETWEEN '2022-08-01' AND '2022-11-01'
GROUP BY
user_pseudo_id
),
combined_data AS (
SELECT
v.user_pseudo_id,
v.visit_days,
r.D7_retention,
r.D30_retention
FROM
user_visits v
JOIN
retention_data r
ON
v.user_pseudo_id = r.user_pseudo_id
)
SELECT
*
FROM
combined_data;
"""df = client.query(query).to_dataframe()
df['visit_days'] = pd.to_numeric(df['visit_days'], errors='coerce').astype(np.float64)
df['D7_retention'] = pd.to_numeric(df['D7_retention'], errors='coerce').astype(np.float64)
df['D30_retention'] = pd.to_numeric(df['D30_retention'], errors='coerce').astype(np.float64)
# 결측치가 있는지 확인하고 제거
df = df.dropna(subset=['visit_days', 'D7_retention', 'D30_retention'])
# 상수항 추가
X = sm.add_constant(df[['visit_days']])
# D7_retention에 대한 로지스틱 회귀 모델 적합
y_D7 = df['D7_retention']
logit_model_D7 = sm.Logit(y_D7, X).fit()
print(logit_model_D7.summary())
# D30_retention에 대한 로지스틱 회귀 모델 적합
y_D30 = df['D30_retention']
logit_model_D30 = sm.Logit(y_D30, X).fit()
print(logit_model_D30.summary())
visit_days_range = np.linspace(df['visit_days'].min(), df['visit_days'].max(), 100)
prob_D7 = logit_model_D7.predict(sm.add_constant(visit_days_range))
prob_D30 = logit_model_D30.predict(sm.add_constant(visit_days_range))
plt.plot(visit_days_range, prob_D7, label='D7 Retention Probability')
plt.plot(visit_days_range, prob_D30, label='D30 Retention Probability', linestyle='--')
plt.xlabel('Visit Days')
plt.ylabel('Retention Probability')
plt.title('Retention Probability vs Visit Days')
plt.legend()
plt.show()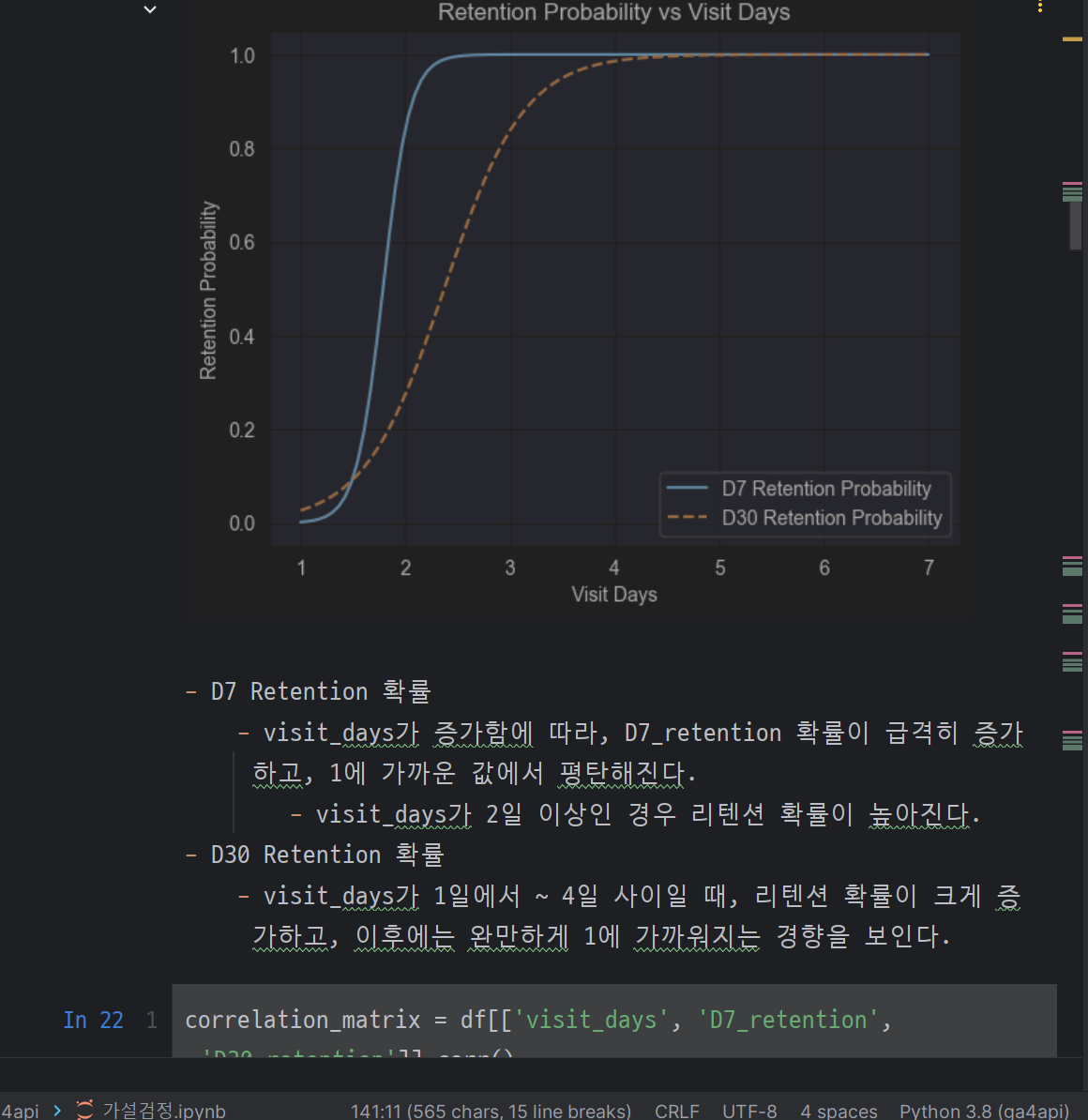
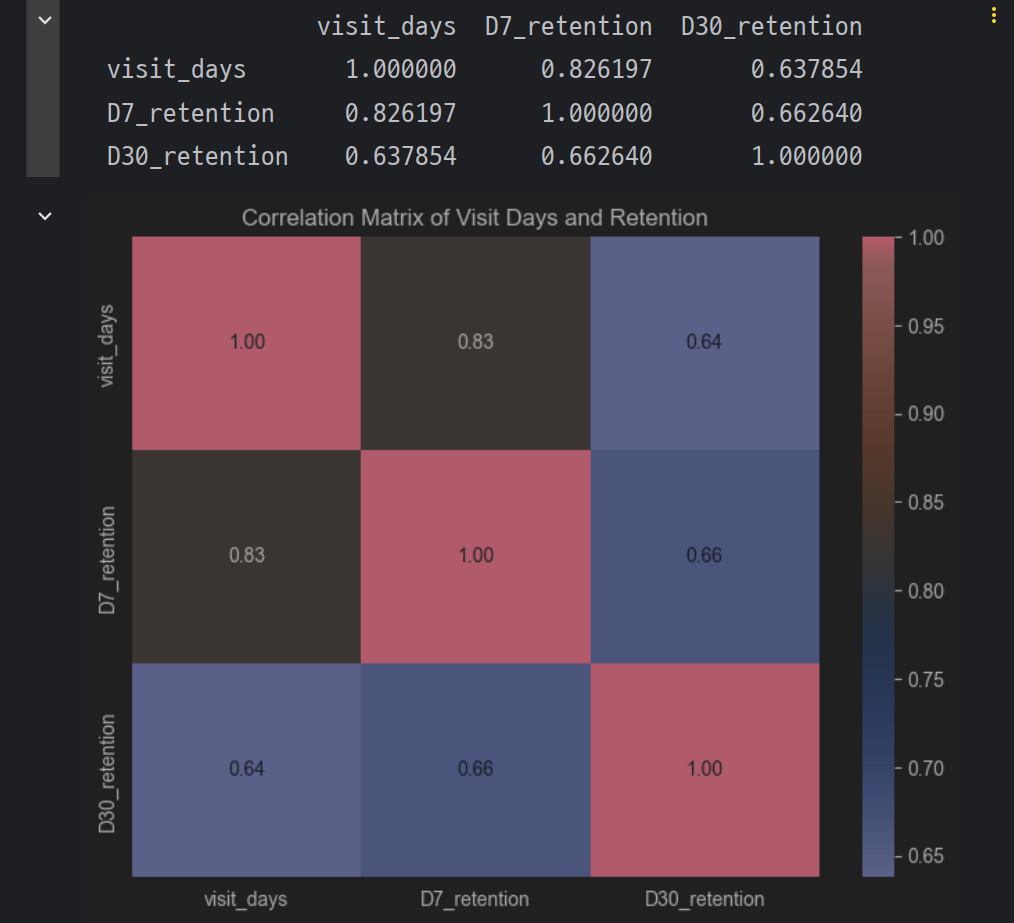
따라서, 방문일수는 Retention과 상관성을 보인다.
가설2. 방문일 수는 user_type에 따라 각기 다른 상관성을 보일 것이다.
결론: user_type은 new_user, current_user는 통계적으로 유의하며, 높은 상관성을 가지나, 휴면 유저, 복귀 유저는 통계적으로 유의미하지 않으며, 낮은 상관성을 띈다.
이렇게 결론을 내놓는 방식이, 적합한 방식인지 궁금합니다.
답변 2
0
0
안녕하세요, 인프런 AI 인턴입니다.
minsubrother님의 질문에 대해 직접적으로 온점에 해당하는 자료를 찾기는 어려웠습니다. 하지만 주제와 밀접한 연결성을 보이는 질문과 답변을 찾아본 결과, 리텐션 과제 연습문제 4번(core_event)에서 비슷한 접근 방식으로 데이터를 분석하고 있으며, 이는 minsubrother님의 질문과 연관성이 있을 수 있습니다. 이 질문에서도 리텐션 분석과 관련된 가설 설정과 쿼리 작성 과정에 대한 깊은 논의가 이루어지고 있습니다.
특히, core_event를 중심으로 한 유저의 행동 또는 이벤트 로깅에 대해 심도 있게 탐구하고 있고, 다양한 유저 유형과 리텐션 간의 관계를 파악하기 위한 분석 과정을 포함하고 있습니다. 이러한 과정들은 분석의 가설 설정 및 검증에 있어 minsubrother님께서 궁금해하시는 방법론적인 문제를 해결하는 데 도움이 될 수 있습니다.
질문자님이 제기한 가설 검증법 적합성: 질문자님이 사용하신 분석 방법은 데이터 과학과 통계 분석 분야에서 널리 채용되는 접근 방식입니다. 특히, 로지스틱 회귀 분석을 통해 특정 조건(방문일 수 같은 지표)이 목표 변수(7일 리텐션 또는 30일 리텐션 같은 지표)에 미치는 영향을 평가하는 것은 유효한 접근법으로 볼 수 있습니다.
리텐션에 영향을 주는 인자 분석: 실제 사례에서도 리텐션과 관련한 다양한 인자를 분석하는 것은 매우 흔한 일입니다. 사용자의 행동 패턴, 활동의 빈도 및 유형, 앱 내 특정 기능의 사용 여부 등 여러 요소가 리텐션에 영향을 미칠 수 있으며, 이를 분석함으로써 제품이나 서비스의 개선 방향을 도출할 수 있습니다.
방문일수와 리텐션 상관성: 방문일수가 리텐션과 높은 상관관계를 보인다는 결과는 흥미롭습니다. 이런 결과는 방문 빈도가 높을수록 사용자의 서비스에 대한 충성도가 높아질 가능성이 크다는 것을 시사합니다. 이러한 정보는 마케팅 전략이나 제품 개선에 있어 중요한 시사점을 제공할 수 있습니다.
저는 질문자님의 이해를 돕고자 지식공유자님의 기존 답변을 참고하여 유사한 답변 링크를 추천해드리고 있습니다.
현재 베타 기능으로 답변이 만족스럽지 않을 수 있는 점 양해 부탁드립니다. 🙏
추가적으로 궁금한 점이 있으시면, 이어서 질문해 주세요. 곧 지식공유자께서 답변해 주실 것입니다.