인프런 커뮤니티 질문&답변
작성한 질문수

캐글 T2-6 질문있습니다.
해결된 질문
작성
·
82
·
수정됨
0
안녕하세요,
공지로 알려주신 캐글 T2-6(시계열데이터가 있는 문제)를 풀고 있는데요!
모델 학습을 하는 과정에서
모델 별 평가 점수가 너무 크게 차이 나서 문의드립니다.
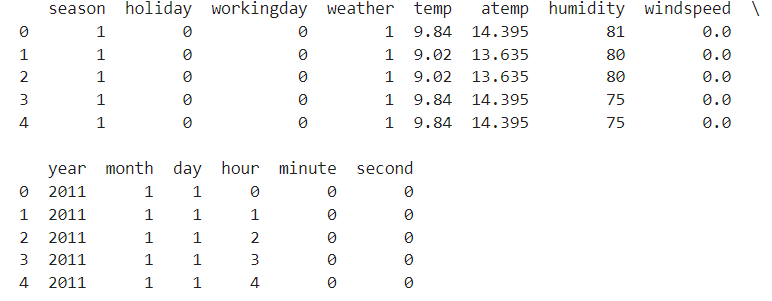
우선 풀이와 조금 다른점이 있다면 , 전처리 과정에서 datetime의 년,월,일 뿐만 아니라 시,분,초까지 칼럼으로 추가했다는 점입니다.
train.head()
 선형회귀로 학습했을 때)
선형회귀로 학습했을 때)
RMSE : 141.97306616836775
R2 : 0.39335324789512727
랜덤포레스트로 학습했을 때)
RMSE : 44.64624546594813 (하이퍼파라미터 튜닝x)
R2 : 0.9400079312167055
모델을 선형회귀로 학습했을 때랑 랜덤포레스트로 학습했을 때 점수차이가 너무 크게 나는데
뭔가 잘못된 부분이 있는걸까요..?
풀이의 모델들 점수가 오히려 선형회귀모델과 비슷한 0.4 정도가 나오는 것으로 보여서
이렇게 유난히 높게 나오는 랜덤포레스트 모델을 선택해도 괜찮은 것인지 궁금합니다.
확인 부탁드립니다!
초스피드 답변 너무 감사합니다!!🙂