인프런 커뮤니티 질문&답변
작성자 없음
작성자 정보가 삭제된 글입니다.

py3_run 오류가 납니다(코드 첨부)
해결된 질문
24.06.20 18:12 작성
·
99
0
안녕하세요, 이전에 테스트 데이터를 넣었을 때 오류가 난다고 했던 수강생입니다. 주구매상품과 구매지점을 넣어서 훈련시키는 건 해결했는데(이전 질문은 해결됨), 수치형 데이터로 훈련시킬 때 아래와 같은 오류메세지가 뜹니다. 농산물은 주구매상품에 있는 변수던데 수치형만 넣었는데도 불구하고 어디서 나온건지.. 이해가 안됩니다..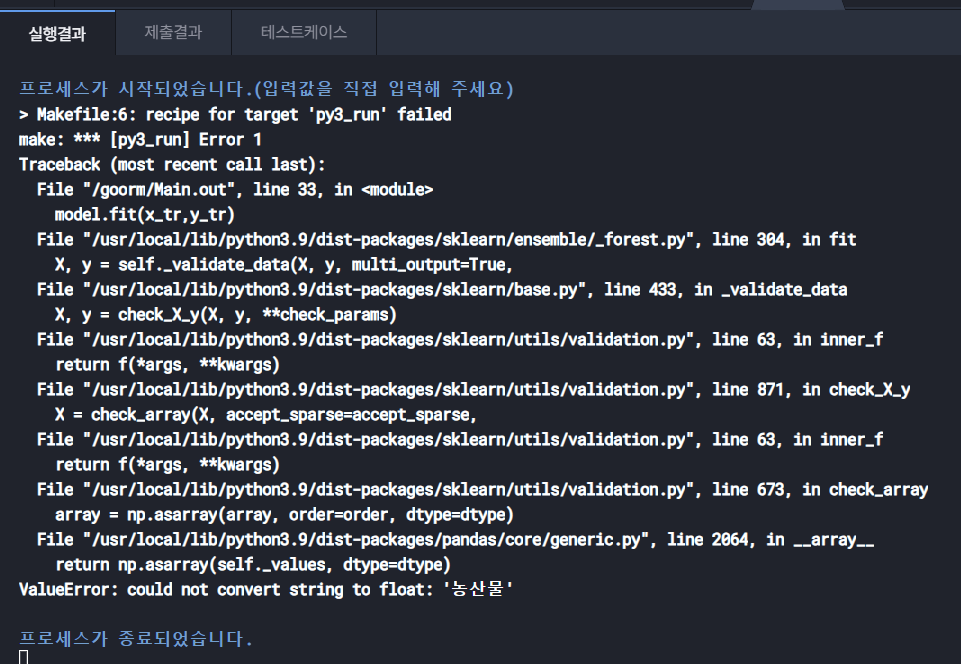 우선 제가 입력했던 코드는 다음과 같습니다. 바쁘신 와중에 확인해주셔서 감사합니다!!
우선 제가 입력했던 코드는 다음과 같습니다. 바쁘신 와중에 확인해주셔서 감사합니다!!
우선 제가 입력했던 코드는 다음과 같습니다. 바쁘신 와중에 확인해주셔서 감사합니다!!
import pandas as pd
pd.set_option('display.max_columns',None)
train = pd.read_csv("data/customer_train.csv")
test = pd.read_csv("data/customer_test.csv")
train['환불금액'] = train['환불금액'].fillna(0)
test['환불금액'] = test['환불금액'].fillna(0)
#cols=['주구매상품','주구매지점']#0.6117
cols=['회원ID','총구매액','최대구매액','환불금액','방문일수','방문당구매건수','주말방문비율','구매주기']
target=train.pop('성별')
#from sklearn.preprocessing import LabelEncoder
#le=LabelEncoder()
#for col in cols:
# train[col]=le.fit_transform(train[col])
# test[col]=le.transform(test[col])
from sklearn.model_selection import train_test_split
x_tr,x_val,y_tr,y_val=train_test_split(train, target, test_size=0.2, random_state=0)
from sklearn.ensemble import RandomForestClassifier
model=RandomForestClassifier()
model.fit(x_tr,y_tr)
pred=model.predict_proba(x_val)
#print(pred)
from sklearn.metrics import roc_auc_score
print(roc_auc_score(y_val, pred[:,1]))
pred = model.predict_proba(test)
submit = pd.DataFrame({
'pred': pred[:,1]
})
submit.to_csv('result.csv', index=False)
print(pd.read_csv('result.csv'))
답변 2
0
퇴근후딴짓
지식공유자
2024. 06. 20. 20:22
obeject가 있어서 에러가 발생했어요
수치형 값만 선택하려고 한 것인가요?
인코딩 방법은 아래와 같습니다.
cols=['주구매상품','주구매지점']
target=train.pop('성별')
from sklearn.preprocessing import LabelEncoder
le=LabelEncoder()
for col in cols:
train[col]=le.fit_transform(train[col])
test[col]=le.transform(test[col])0
2024. 06. 20. 18:13
import pandas as pd
pd.set_option('display.max_columns',None)
train = pd.read_csv("data/customer_train.csv")
test = pd.read_csv("data/customer_test.csv")
train['환불금액'] = train['환불금액'].fillna(0)
test['환불금액'] = test['환불금액'].fillna(0)
#cols=['주구매상품','주구매지점']#0.6117
cols=['회원ID','총구매액','최대구매액','환불금액','방문일수','방문당구매건수','주말방문비율','구매주기']
target=train.pop('성별')
#from sklearn.preprocessing import LabelEncoder
#le=LabelEncoder()
#for col in cols:
# train[col]=le.fit_transform(train[col])
# test[col]=le.transform(test[col])
from sklearn.model_selection import train_test_split
x_tr,x_val,y_tr,y_val=train_test_split(train, target, test_size=0.2, random_state=0)
from sklearn.ensemble import RandomForestClassifier
model=RandomForestClassifier()
model.fit(x_tr,y_tr)
pred=model.predict_proba(x_val)
#print(pred)
from sklearn.metrics import roc_auc_score
print(roc_auc_score(y_val, pred[:,1]))
pred = model.predict_proba(test)
submit = pd.DataFrame({
'pred': pred[:,1]
})
submit.to_csv('result.csv', index=False)
print(pd.read_csv('result.csv'))
2024. 06. 20. 18:14
본문 코드가 깨져서 댓글로 다시 올립니다!