인프런 커뮤니티 질문&답변
작성한 질문수

3회 기출유형(작업형2) 채점부분 질문
해결된 질문
작성
·
99
0
채점부분 코드 돌리려는데, 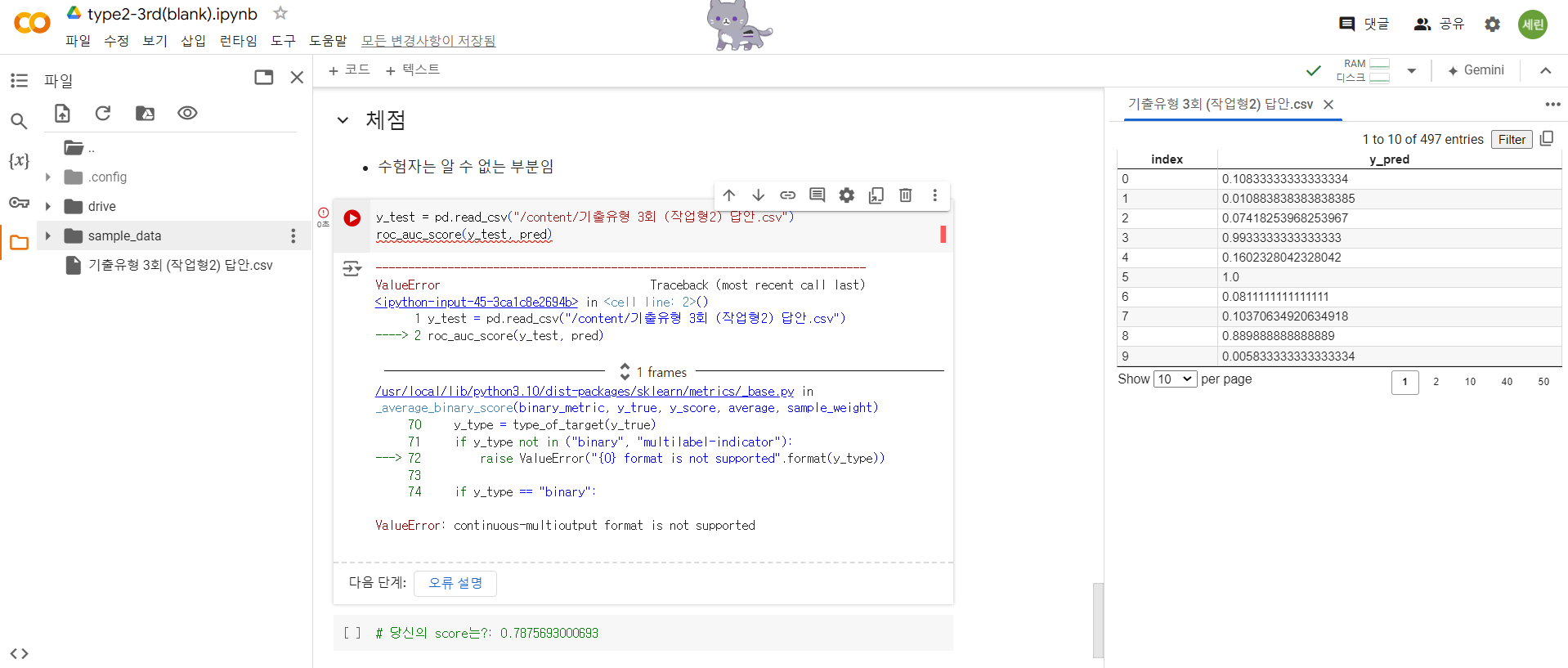
이렇게 오류가 뜨네요.
제 풀이는
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import roc_auc_score
df1 = pd.read_csv('/content/drive/MyDrive/bigdata(빅분기 놀이터)/기출문제/3회/train.csv')
# print(df1.head())
# print(df1.info())
# print(df1.describe())
df2 = pd.read_csv('/content/drive/MyDrive/bigdata(빅분기 놀이터)/기출문제/3회/test.csv')
# print(df2.head())
# print(df2.info())
# print(df2.describe())
df1['TravelInsurance'] = df1['TravelInsurance'].astype('category')
x = df1.drop('TravelInsurance', axis=1)
y = df1['TravelInsurance']
x_encoded = pd.get_dummies(x)
x_train, x_valid, y_train, y_valid = train_test_split(x_encoded.drop('Unnamed: 0', axis=1), y, test_size=0.25)
md = RandomForestClassifier(n_estimators=300)
md.fit(x_train, y_train)
pred = md.predict(x_valid)
cm = confusion_matrix(y_valid, pred, labels=[1,0])
print(cm)
print(accuracy_score(y_valid, pred))
print(precision_score(y_valid, pred))
print(recall_score(y_valid, pred))
print(f1_score(y_valid, pred))
print(roc_auc_score(y_valid, pred))
x_test = df2
x_test_encoded = pd.get_dummies(x_test)
md = RandomForestClassifier(n_estimators=300)
md.fit(x_encoded.drop('Unnamed: 0', axis=1), y)
pred = md.predict_proba(x_test_encoded.drop('Unnamed: 0', axis=1))
# print(pred)
result = pd.DataFrame({'y_pred' : pred[:, 1]}).reset_index()
print(result)
result.to_csv('기출유형 3회 (작업형2) 답안.csv', index = False)
입니다!
답변 1
0
마지막부분은 시험에서는 작성할 코드는 아니라서 무시해도 되나
에러로 봤을때는 pred 또는 y_test가 1개 컬럼이 아닌 데이터프레임(2차원 배열)형태로 보여집니다.