인프런 커뮤니티 질문&답변
작성한 질문수

작업형1 모의문제2
해결된 질문
작성
·
103
0
 안녕하세요, 코린이입니다
안녕하세요, 코린이입니다
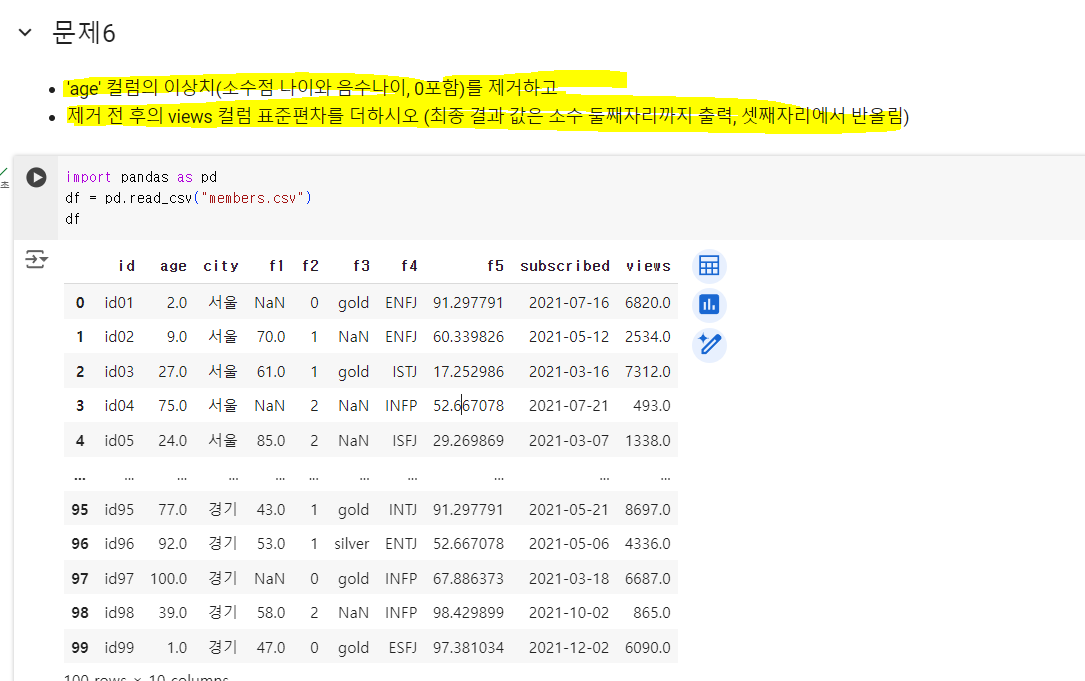
문제가 age 컬럼의 이상치를 제거하고 제거전후 views 컬럼 편차를 구하는거고..
age 컬럼 이상치를 제거하면 views 컬럼에 있는 age 이상치 행도 같이 날라가나요 ?
그래서 제거전후 편차를 구하게 되는걸까요 ?
import pandas as pd df = pd.read_csv("members.csv") r1 = df['views'].std() cond = df['age'] <= 0 # print(df.shape) df = df[~cond] # print(df.shape) # print(df.shape) cond = df['age'] == round(df['age'],0) # 소숫점 나이 구하기, 반올림 했을 때 같으면 정수형 , 다르면 소수점 df = df[cond] # print(df.shape) r2 = df['views'].std() print(round(r1 + r2, 2))
답변 1
0
정형 데이터는 행과 열로 구성된 표입니다.
제거 방식은 행을 제거하거나 열(컬럼)을 제거하는 방식이 있습니다.
age 컬럼의 이상치를 제거하는 과정에서 해당 이상치를 포함하는 행 전체가 데이터프레임에서 제거됩니다.
cond = df['age'] <= 0 코드의 결과는 True 또는 False 입니다. 이 조건을 데이터프레임에 넣으면 df[cond] True인 행만 출력하게 되요.
여기서 df = df[~cond] 와 같이 ~ 표시를 붙였으니 반대로 False 행만 출력합니다.