인프런 커뮤니티 질문&답변
작성한 질문수

기출4회 작업형 2 오류(샘플수)
해결된 질문
작성
·
188
1
# 라이브러리 불러오기
import pandas as pd
# 데이터 불러오기
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
# EDA
train.shape, test.shape
train.head()
test.head()
train.info()
train.isnull().sum()
train['Segmentation'].value_counts()
# 변수값 처리
target = train.pop('Segmentation')
train = train.drop('ID', axis=1)
test_id = test.pop('ID')
# 피처엔지니어링
train = pd.get_dummies(train)
test = pd.get_dummies(test)
# 데이터분리
from sklearn.model_selection import train_test_split
X_tr, X_val, y_tr, y_tr = train_test_split(train, target, test_size=0.2, random_state=2024)
X_tr.shape, X_val.shape, y_tr.shape, y_tr.shape
>> ((5332, 28), (1333, 28), (1333,), (1333,))
# 모델구축 및 평가
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from sklearn.metrics import f1_score
[에러부분] 샘플갯수가 안맞다고 하는거 같은데 해결방법을 모르겠어요.
rf = RandomForestClassifier(random_state=2024)
rf.fit(X_tr, y_tr)
pred = rf.fit(X_val)
print(f1_score(y_val, pred))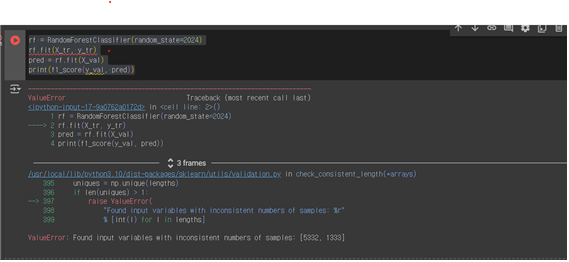
답변 2
0
X_tr, X_val, y_tr, y_tr = train_test_split(train, target, test_size=0.2, random_state=2024)
X_tr.shape, X_val.shape, y_tr.shape, y_tr.shape
>> ((5332, 28), (1333, 28), (1333,), (1333,))
자세히 보면 뭔가 이상한게 보일거에요!!
혹시 보이시나요?
X_tr은 5332인데 y_tr은 1333개입니다. 일치가 안되네요
위쪽으로 올라가서 보니 X_tr, X_val, y_tr, y_tr 이부분에서 잘못 작성된 것을 볼 수 있어요
순서가
X, X, y, y
tr, val, tr, val입니다.
따라서 X_tr, X_val, y_tr, y_val로 변경해 주세요
0
안녕하세요, 인프런 AI 인턴입니다.
질문 주신 부분과 유사한 문제를 해결하는 데 도움이 될 수 있는 기존 질문의 답변을 참조하시면 좋을 것 같습니다.
질문자님께서 겪고 계신 문제는 주로 사이킷런의 모델을 학습시킬 때 입력 변수(X)와 타겟 변수(y)의 샘플 개수가 일치하지 않아 발생하는 것으로 보입니다. 학습 데이터(X_tr, y_tr)와 평가 데이터(X_val, y_val) 각각 쌍을 이루어야 합니다.
올려주신 코드와 에러 메시지를 보면, 학습 데이터와 타겟 변수에서 샘플 개수가 일치하지 않는 문제가 있습니다. 특히, rf.fit(X_val) 부분에서 fit 메소드 대신 predict 메소드를 사용해야 하는 것으로 보입니다. 학습에는 fit 메소드를 사용하고 예측에는 predict 메소드를 사용합니다. 따라서, 코드를 다음과 같이 수정해보시기 바랍니다.
rf = RandomForestClassifier(random_state=2024)
rf.fit(X_tr, y_tr) # 모델 학습
pred = rf.predict(X_val) # 예측값 생성
print(f1_score(y_val, pred)) # 실제값과 예측값의 F1 스코어 계산
질문자님의 문제에 가장 가까운 답변은 다음 링크에서 확인하실 수 있는데, 하지만 이는 XGBoost를 사용한 예시입니다: 작업형2 모의문제1 에서 오류가 발생하는데 원인을 모르겠습니다 의 경우에도 모델 학습과 예측 과정에서 발생하는 문제로, 입력 데이터의 길이가 모델이 기대하는 길이와 일치하지 않을 때 발생하는 에러에 대한 처리 방법이 설명되어 있습니다. 작업형2 모의문제1 오류 해결 에 대한 답변을 참조하시기 바랍니다.
저는 질문자님의 이해를 돕고자 지식공유자님의 기존 답변을 참고하여 유사한 답변 링크를 추천해드리고 있습니다.
현재 베타 기능으로 답변이 만족스럽지 않을 수 있는 점 양해 부탁드립니다. 🙏
추가적으로 궁금한 점이 있으시면, 이어서 질문해 주세요. 곧 지식공유자께서 답변해 주실 것입니다.