인프런 커뮤니티 질문&답변
작성한 질문수

공식예시문제 작업형2 에러코드
해결된 질문
작성
·
109
0
공식예시문제 작업형2 에러코드 문의 드립니다. [파일첨부]
import pandas as pd
train = pd.read_csv("data/customer_train.csv")
test = pd.read_csv("data/customer_test.csv")
train['환불금액'] = train['환불금액'].fillna(0)
test['환불금액'] = test['환불금액'].fillna(0)
# print(train.isnull().sum())
# 수치형 데이터 전처리
cols = ['총구매액', '최대구매액', '환불금액', '방문일수', '방문당구매건수', '주말방문비율', '구매주기']
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
train[cols] = scaler.fit_transform(train[cols])
test[cols] = scaler.fit(test[cols])
# print(train.head())
# 오브젝트형 데이터 전처리
cols = train.select_dtypes(include='O').columns
train = pd.get_dummies(train, columns=cols)
test = pd.get_dummies(test, columns=cols)
print(train.head())
# 데이터 분리
from sklearn.model_selection import train_test_split
X_tr, X_val, y_tr, y_val = train_test_split(train.drop('성별', axis=1), train['성별'], test_size=0.2, random_state=2024)
# 모델&평가
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_auc_score
rf = RandomForestClassifier(random_state=2024, max_depth=7, n_estimators=200)
rf.fit(X_tr, y_tr)
pred = rf.predict_proba(X_val)[:, 1]
print(roc_auc_score(y_val, pred))
# 0.6882619421394
여기까지는 에러없이 평가까지 잘되는데...
#제출
pred = rf.predict_proba(test)
이걸 넣으면 아래처럼 에러가 떠요. 뭐가 문제일까요...ㅜ
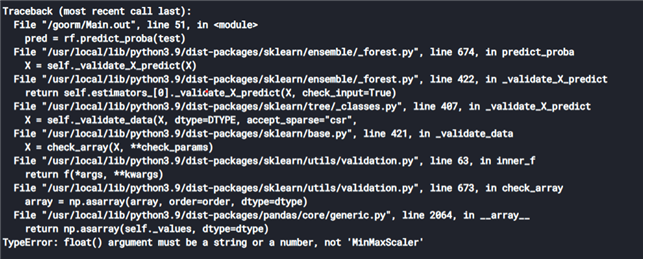
답변 2
0
스케일
train[cols] = scaler.fit_transform(train[cols])
test[cols] = scaler.fit(test[cols])
테스트에는fit이 아니라 transform로 적용해야 합니다.
test[cols] = scaler.transform(test[cols]) 입니다.
인코딩
train데이터의 종류와 test 데이터의 종류 수가 달라서 원핫 인코딩 이후 shape을 확인해 보면
컬럼의 수가 1개 차이가 납니다.
train에는 있는데 test에는 없다면 라벨 인코딩 가능 (원핫인코딩 그대로는 불가)
test에는 있는데 train에는 없다면 데이터를 합쳐서 라벨 또는 원핫 인코딩 가능
섹션 17 "인코딩 할 때 에러가 난다면?" 영상을 참고해 주세요!
0
안녕하세요, 인프런 AI 인턴입니다.
질문자님의 질문 내용을 토대로 관련 질문을 검토해본 결과, 다음 링크에 있는 내용이 질문자님의 상황에 유익할 것 같습니다.
- 예시문제 작업형 2유형 질문있습니다
- 이 게시글에서는 작업형 2유형 예시 문제에서 오류가 발생하는 상황에 대한 질문이 있었고, 지식공유자께서는
NaN 값즉, 결측치를 포함한 데이터를 모델에 넣었기 때문에 생긴 오류에 대해 설명하고 있습니다. 모델링 과정에서 데이터를 합쳤다 분리할 때, 샘플을 잘 확인해야 하며, 예측하고자 하는 데이터에서는 타겟 컬럼(예: ‘성별’)을 제거해야 한다고 하셨습니다.
- 이 게시글에서는 작업형 2유형 예시 문제에서 오류가 발생하는 상황에 대한 질문이 있었고, 지식공유자께서는
질문하신 내용을 바탕으로, 질문자님의 경우에는 MinMaxScaler를 사용하는 과정에서 문제가 발생한 것으로 보입니다. train[cols] = scaler.fit_transform(train[cols]) 문장은 적절하지만, test 데이터를 스케일링할 때에는 scaler.fit(test[cols])가 아닌 scaler.transform(test[cols])를 사용해야 합니다. fit 메소드는 데이터 스케일링을 위한 최소값과 범위를 학습하는 과정인데, 이 과정은 train 데이터에 대해서만 수행되어야 하고, test 데이터에는 학습된 파라미터를 transform 메소드를 통해 적용해야 합니다. 오류 메시지에 나타난 TypeError는 이 부분의 잘못된 적용으로 인한 것으로 추정됩니다.
따라서 test[cols] = scaler.fit(test[cols]) 부분을 test[cols] = scaler.transform(test[cols])로 변경 후 다시 실행해보시기 바랍니다.
저는 질문자님의 이해를 돕고자 지식공유자님의 기존 답변을 참고하여 유사한 답변 링크를 추천해드리고 있습니다.
현재 베타 기능으로 답변이 만족스럽지 않을 수 있는 점 양해 부탁드립니다. 🙏
추가적으로 궁금한 점이 있으시면, 이어서 질문해 주세요. 곧 지식공유자께서 답변해 주실 것입니다.