인프런 커뮤니티 질문&답변
작성한 질문수

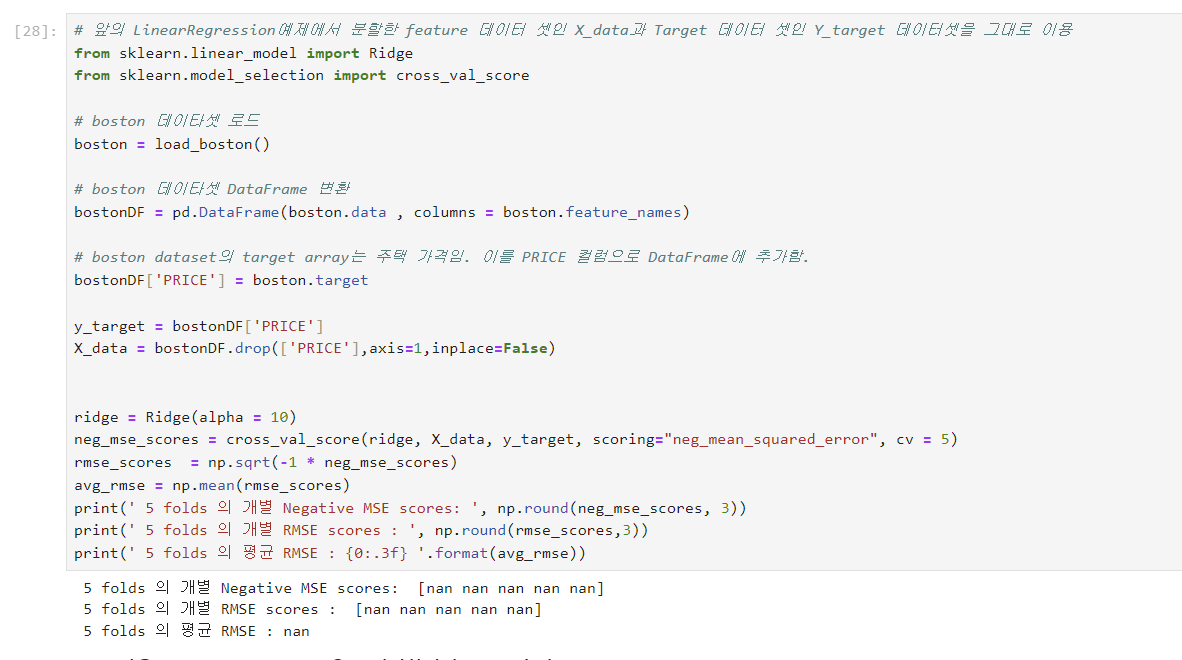 이렇게 nan으로 다 뜨는데 이유가 무엇일까요..
이렇게 nan으로 다 뜨는데 이유가 무엇일까요.. 
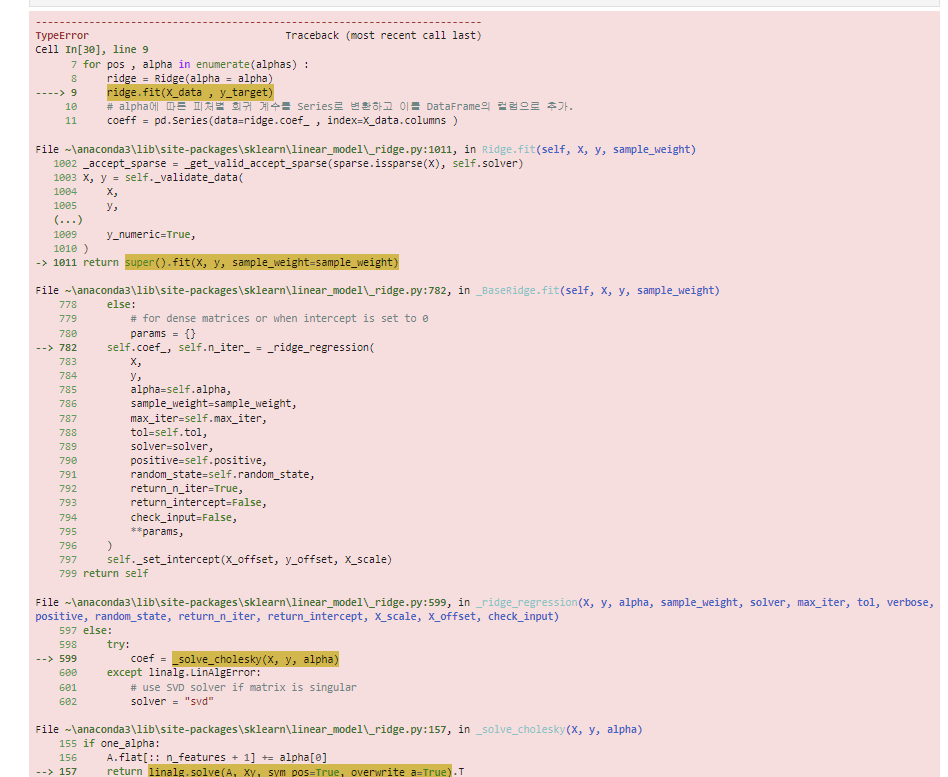 이렇게 에러가 뜹니다. 참고로 주신 코드 그대로 돌렸습니다ㅠ
이렇게 에러가 뜹니다. 참고로 주신 코드 그대로 돌렸습니다ㅠ답변 3
0
안녕하세요 .
저역시 해당 문제를 겪어 그냥 넘어 갈까 하다가 나중의 실습문제도 동일하게 겪을거 같아 근본적인 원인을 파악해보고자
에러의 내용을 확인해 보았습니다.
해당 에러를 보면 결국 pandas는 scipy 모듈을 호출합니다.
즉 pandas와 scipy 모듈은 서로 종속성이 있다는 의미이어서
sklearn과 호환되는 scipy 버전을 찾아야 합니다.
pip install scipy==1.7.3 을 설치하니 해당 문제가 해결되었습니다.
강사님 강의는 잘 듣고 있습니다.
조금 아쉬운 점은 conda를 사용하면 대충 다 깔리기에 실제 강의에 사용된 종속성을 가진 패키지의 버전은 명시할 필요가 있지 않을까 합니다.
0
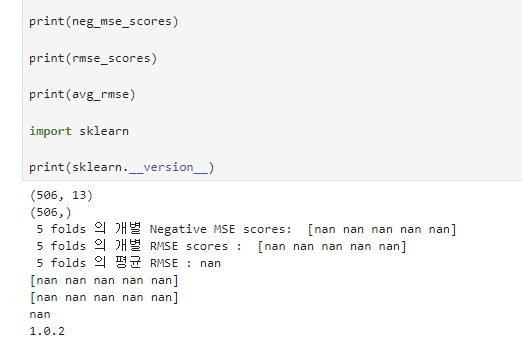 이렇게 나옵니다!
이렇게 나옵니다!0
안녕하십니까.
음. nan이 나올 이유가 없을 것 같습니다만.
X_data = bostonDF.drop(...) 다음에
print(X_data.shape) 하셔서 X_data값이 나오는지 확인해 보시겠습니까?
X_data 값이 나오면, print(y_target.shape) 하셔서 y_target값이 나오는지도 확인해 보시겠습니까?
감사합니다.
데이터는 문제가 없어 보이는데,
print(neg_mse_scores)
print(rmse_score)
print(avg_rmse)
하셔서 어디서 nan이 나오는지 확인해 보시겠습니까,
그리고
import sklearn
print(sklearn.__version__) 하셔서 sklearn 버전도 부탁드립니다.
 이렇게 나옵니다!
이렇게 나옵니다!음, cross_val_score() 리턴값이 nan이 나오는 군요.
원인은 잘 모르겠군요. 해당 실습 코드는 scikit learn 1.0.2 에서 문제없이 동작합니다.
혹 최근에 pandas나 numpy 또는 다른 패키지를 설치하거나 upgrade 하신적이 있는지요?
현재 conda 환경에서 수행이 되지 않으면 colab등의 환경에서 실습코드를 수행해 보십시요. 단 colab에서는 pip install scikit-learn==1.0.2 로 downgrade한 후에 커널을 재 기동하여 수행하셔야 합니다. 이렇게 해보시고 안되시면 다시 글 부탁드립니다.
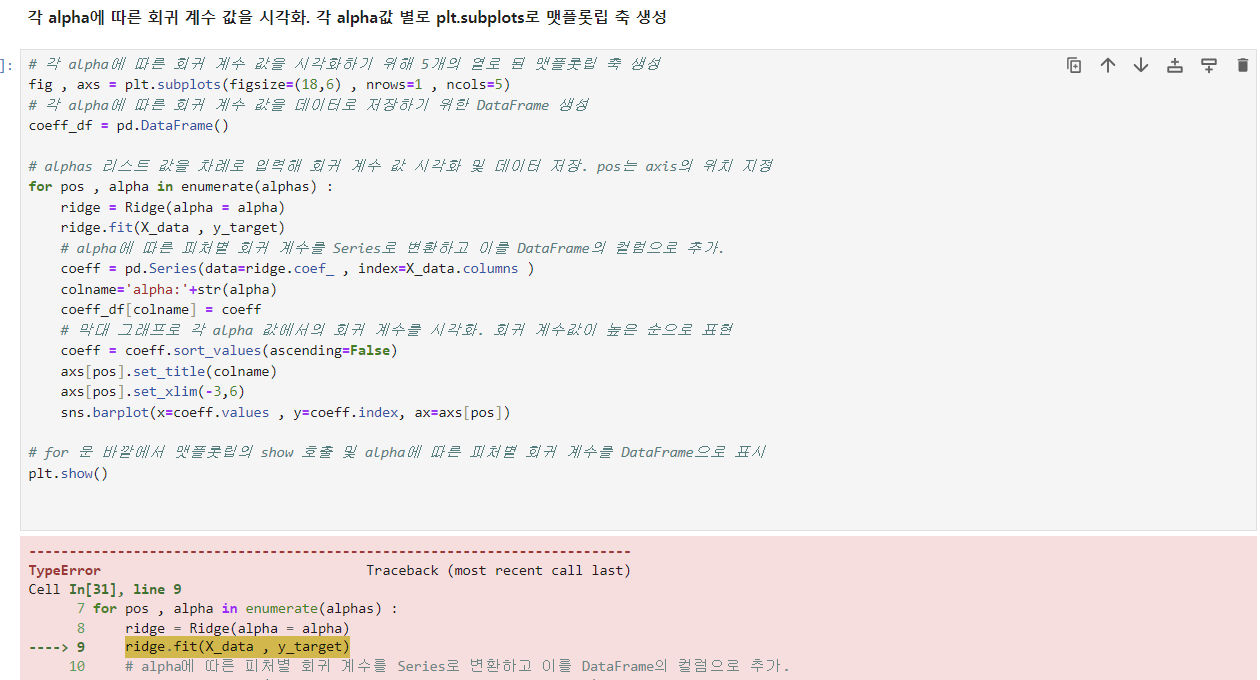

제 생각엔 다른 패키지를 설치하면서 넘파이가 꼬인것 같습니다.
Load boston 데이타세트 말고 이후 강의의 다른 데이터 세트로 회귀 실습 해보시고 여전히 오류가 발생하면 아예 아나콘다를 다 날리고 재 설치 하셔야 할것 같습니다
Load boston 데이타세트에서만 오류 발생하면 다시 글 올려주세요. 그리고 오류 메시지는 캡터 뜨지 마시고 텍스트로 여기에 올려주세요
새로운 Conda 환경을 구성하는게 베스트이긴 한데, 그럴려면 scikit learn == 1.0.2 부터 pandas 등 필요한 라이브러리를 직접 설치하셔야 합니다. 또 jupyter notebook에서 해당 conda 환경을 잡고 올라올 수 있도록 작업이 필요합니다. 인터넷등을 참조해서 작업이 가능하시다면 한번 해보시는 것도 좋을 것 같습니다. 잘 안되시면 그때 새로 conda를 설치하시면 어떨까 싶습니다.