인프런 커뮤니티 질문&답변
작성한 질문수

오토인코더를 특성 추출기로 사용하는 방법에 대해 질문
작성
·
150

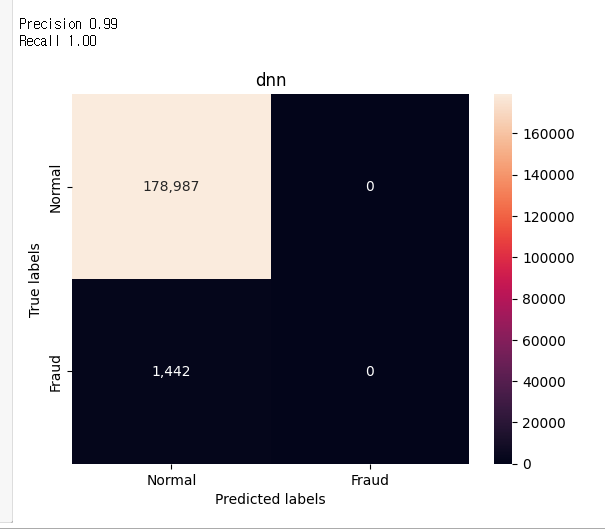
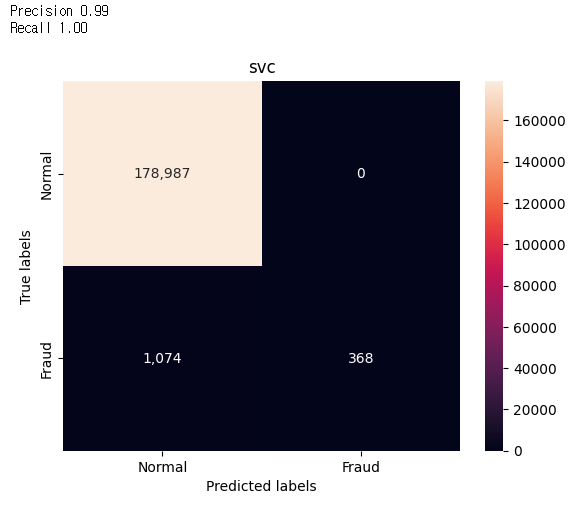
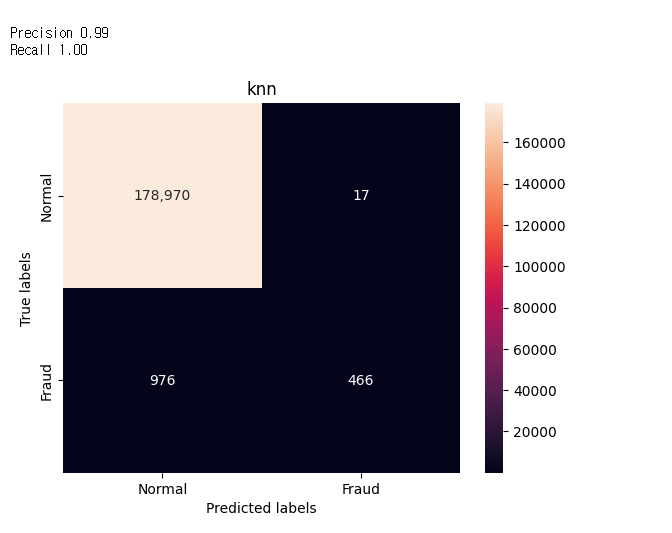
답변 1
0
YoungJea Oh
지식공유자
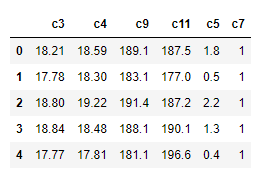
일단 c7을 1, 2 가 아니라 0, 1 로 바꾸시기 바랍니다. 교재에서는 다른 모든 column 값 들이 scaling 되어 있고 amount 만 큰 값이라서 log scale을 잡아 줬지만 수강자님의 데이터는 각 column 별로 log scale 을 잡을 성격이 아니라 전체적으로 standard scaling을 하시는 것이 맞는 것 같습니다. c7 이 label 이라면 c7 을 y 로 분리 하시고 나머지 X column 들에 대해 sklearn.preprocessing.StandardScaler 를 이용해서 normalize 하시기 바랍니다. 감사합니다.
YoungJea Oh
지식공유자
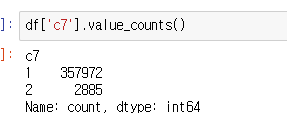
c7을 label 로 사용하실 것 아닌가요? 2진 분류 모델은 sigmoid 를 activation 함수로 사용하고 binary crossentropy loss 를 이용하므로 0, 1 로 encoding 되어야 합니다. 감사합니다.
c7을 1,2가 아닌 0,1로 바꾸라는 말씀을 하셨는데 이유가 먼가요?