인프런 커뮤니티 질문&답변
작성한 질문수

질문드려요
작성
·
161
·
수정됨
0
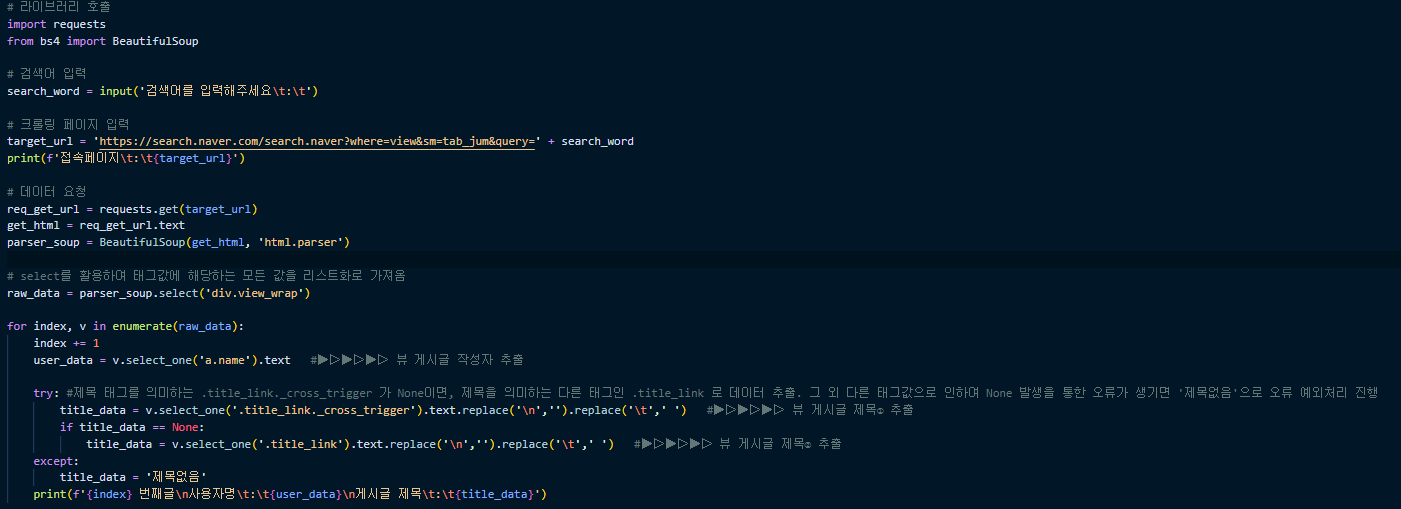 강의 녹화 시점때와 다르게 현재 뷰 메뉴 태그값들이 모두 바뀐것같아서 강사님 강의에 따라 위 코드를 작성하였는데
강의 녹화 시점때와 다르게 현재 뷰 메뉴 태그값들이 모두 바뀐것같아서 강사님 강의에 따라 위 코드를 작성하였는데
v['href']를 사용하면 오류가 나와요...
v.select_one('a')['href'] 을 입력하면 #으로 나오고요...확인좀부탁드릴게여..
# 라이브러리 호출
import requests
from bs4 import BeautifulSoup
# 검색어 입력
search_word = input('검색어를 입력해주세요\t:\t')
# 크롤링 페이지 입력
target_url = 'https://search.naver.com/search.naver?where=view&sm=tab_jum&query=' + search_word
print(f'접속페이지\t:\t{target_url}')
# 데이터 요청
req_get_url = requests.get(target_url)
get_html = req_get_url.text
parser_soup = BeautifulSoup(get_html, 'html.parser')
# select를 활용하여 태그값에 해당하는 모든 값을 리스트화로 가져옴
raw_data = parser_soup.select('div.view_wrap')
for index, v in enumerate(raw_data):
index += 1
user_data = v.select_one('a.name').text #▶▷▶▷▶▷ 뷰 게시글 작성자 추출
try: #제목 태그를 의미하는 .title_link._cross_trigger 가 None이면, 제목을 의미하는 다른 태그인 .title_link 로 데이터 추출. 그 외 다른 태그값으로 인하여 None 발생을 통한 오류가 생기면 '제목없음'으로 오류 예외처리 진행
title_data = v.select_one('.title_link._cross_trigger').text.replace('\n','').replace('\t',' ') #▶▷▶▷▶▷ 뷰 게시글 제목① 추출
if title_data == None:
title_data = v.select_one('.title_link').text.replace('\n','').replace('\t',' ') #▶▷▶▷▶▷ 뷰 게시글 제목② 추출
except:
title_data = '제목없음'
print(f'{index} 번째글\n사용자명\t:\t{user_data}\n게시글 제목\t:\t{title_data}')
해결하셨다니 다행입니다!
다른 질문 생기면 언제든지 올려주세요~