인프런 커뮤니티 질문&답변
작성한 질문수

피처별 회귀계수 시각화
작성
·
276
0
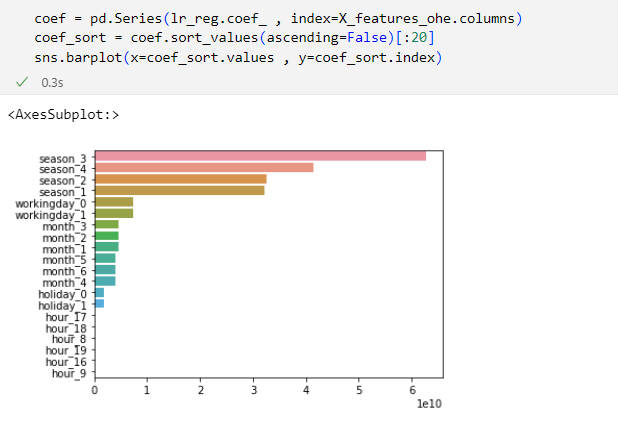
강의 회귀 실습 1: 자전거 대여(공유) 수요 예측 -02에서 19분 52초 경에 나오는 선형 회귀의 피처별 회귀계수 시각화 부분에서 저 회귀계수 값들이 다르게 나올 수가 있는지, 질문드립니다.
github의 주피터노트북 코드 다운로드 받아서 그대로 시행했는데 LinearRegression/Lasso/Ridge 각 회귀에 대한 RMSLE, RMSE, MAE까지는 값이 정확히 동일하게 나오는데
회귀 계수의 값을 보려고 lr_reg.coef_ 부분에서 결과가 다르게 나옵니다. 상식적으로 회귀 모형에서 이런 결과가 나올 수가 없다고 생각되는데 무슨 이유인지 모르겠어서 질문드립니다! 감사합니다
답변 2
0
안녕하세요. 너무 좋은 강의 잘 듣고 있습니다.
Bike Sharing Demend 예제소스 에러 질문이 있어서요..
[ 로그 변환, 피처 인코딩, 모델 학습/예측/평가 ]
from sklearn.model_selection import train_test_split , GridSearchCV
from sklearn.linear_model import LinearRegression , Ridge , Lasso
y_target = bike_df['count']
X_features = bike_df.drop(['count'],axis=1,inplace=False)
X_train, X_test, y_train, y_test = train_test_split(X_features, y_target, test_size=0.3, random_state=0)
lr_reg = LinearRegression()
lr_reg.fit(X_train, y_train)
pred = lr_reg.predict(X_test)
evaluate_regr(y_test ,pred)
에러
---------------------------------------------------------------------------
DTypePromotionError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_19124\3974685920.py in <module>
11 lr_reg = LinearRegression()
12
---> 13 lr_reg.fit(X_train, y_train)
14 pred = lr_reg.predict(X_test)
15
D:\dev03\anaconda\lib\site-packages\sklearn\linear_model\_base.py in fit(self, X, y, sample_weight)
660 accept_sparse = False if self.positive else ["csr", "csc", "coo"]
661
--> 662 X, y = self._validate_data(
663 X, y, accept_sparse=accept_sparse, y_numeric=True, multi_output=True
664 )
D:\dev03\anaconda\lib\site-packages\sklearn\base.py in _validate_data(self, X, y, reset, validate_separately, **check_params)
579 y = check_array(y, **check_y_params)
580 else:
--> 581 X, y = check_X_y(X, y, **check_params)
582 out = X, y
583
D:\dev03\anaconda\lib\site-packages\sklearn\utils\validation.py in check_X_y(X, y, accept_sparse, accept_large_sparse, dtype, order, copy, force_all_finite, ensure_2d, allow_nd, multi_output, ensure_min_samples, ensure_min_features, y_numeric, estimator)
962 raise ValueError("y cannot be None")
963
--> 964 X = check_array(
965 X,
966 accept_sparse=accept_sparse,
D:\dev03\anaconda\lib\site-packages\sklearn\utils\validation.py in check_array(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator)
663
664 if all(isinstance(dtype, np.dtype) for dtype in dtypes_orig):
--> 665 dtype_orig = np.result_type(*dtypes_orig)
666
667 if dtype_numeric:
DTypePromotionError: The DType <class 'numpy.dtypes.DateTime64DType'> could not be promoted by <class 'numpy.dtypes.Float64DType'>. This means that no common DType exists for the given inputs. For example they cannot be stored in a single array unless the dtype is `object`. The full list of DTypes is: (<class 'numpy.dtypes.DateTime64DType'>, <class 'numpy.dtypes.Int64DType'>, <class 'numpy.dtypes.Int64DType'>, <class 'numpy.dtypes.Int64DType'>, <class 'numpy.dtypes.Int64DType'>, <class 'numpy.dtypes.Float64DType'>, <class 'numpy.dtypes.Float64DType'>, <class 'numpy.dtypes.Int64DType'>, <class 'numpy.dtypes.Float64DType'>, <class 'numpy.dtypes.Int64DType'>, <class 'numpy.dtypes.Int64DType'>, <class 'numpy.dtypes.Int64DType'>, <class 'numpy.dtypes.Int64DType'>, <class 'numpy.dtypes.Int64DType'>, <class 'numpy.dtypes.Int64DType'>)
0
안녕하십니까,
실습 코드와 동일하게 코드를 수행하는 데 강의 결과와 다른 피처 중요도 값이 나오는 건지요?
그렇다면 현재 사용하시는 사이킷런 버전을 알 수 있을까요? 아래와 같이 수행해 주시면 됩니다.
import sklearn
print(sklearn.__version__)
감사합니다.
음, 좀 납득이 안되는 군요.
실습 코드 그대로 수행하고, RMSLE, RMSE, MAE 값까지 다 강의 결과와 동일하게 나오는데, 피처 중요도가 다르게 나오다니....
RMSLE, RMSE, MAE 값까지 다 강의 결과와 동일하게 나온다는 것은 모델이 강의에서 사용한 모델과 동일한 결과라는 건데, 피처 중요도가 다르면 RMSLE/RMSE/MAE가 다르게 나올 텐데, 어떻게 된 영문인지 저도 잘 모르겠군요.
다시 한번 실습 코드가 변경되었는지 확인해 보시고, 그래도 피처 중요도가 다르다면 강의 실습 코드를 다시 다운로드 받으신 후에 다시 수행해 보시고 결과 업데이트 부탁드립니다.
죄송하지만 다시 보아도 정말 정확히 똑같이 진행했는데 다른 결과가 나옵니다.
(참고로 이 페이지 들어가보시면 제 주피터노트북 html 출력 파일이 있습니다.)
https://greenjade.tistory.com/56
영문을 모르겠지만 다른 학생들로부터는 이러한 질문이 나오지 않은 것으로 보아 제가 시행한 코드에 문제가 있는 것이 맞는 것 같습니다. 그러나 무엇이 오류인지는 찾기가 어려운 것 같습니다
음, 그렇군요.
너무 feature importance 가 직관에 반하는 결과가 나오더라도, 너무 큰 의미를 두시지 않아도 될 것 같습니다.
물론 강의 실습과 다른 결과가 나와서, 혹 모델이 잘못 만들어지지는 않았는지 염려가 되실 수는 있지만, 일단 모델 평가 성능 수치만 참조하시면 좋을 것 같습니다.
생각보다 머신러닝 모델이 중시하는 피처가 우리가 직관적으로 좋을 거라 판단되는 피처와 다른 경우들이 많습니다. feature importance 결과를 굳이 강의 실습과 동일하게 하시느라 많은 시간을 소비하실 필요는 없을 것 같고, 전체적인 맥락을 이해하는 수준에서 마무리 하시면 어떨까 싶습니다.
감사합니다.
네 실습코드 그대로 수행했는데 강의 결과와 다른 피처 중요도 값이 나왔습니다.
현재 사용하는 사이킷런 버전은 1.0.2라고 나옵니다.