인프런 커뮤니티 질문&답변
작성한 질문수

Encoder-Decoder 실습 질문드립니다.
작성
·
251
0
Encoder-Decoder 실습 질문드립니다.
직접 실습을 하면서 강의영상과 실습 결과의 차이가 커서 모델 성능이 떨어져보이는데 어떤 부분을 건드려봐야할까요?

답변 2
0
0
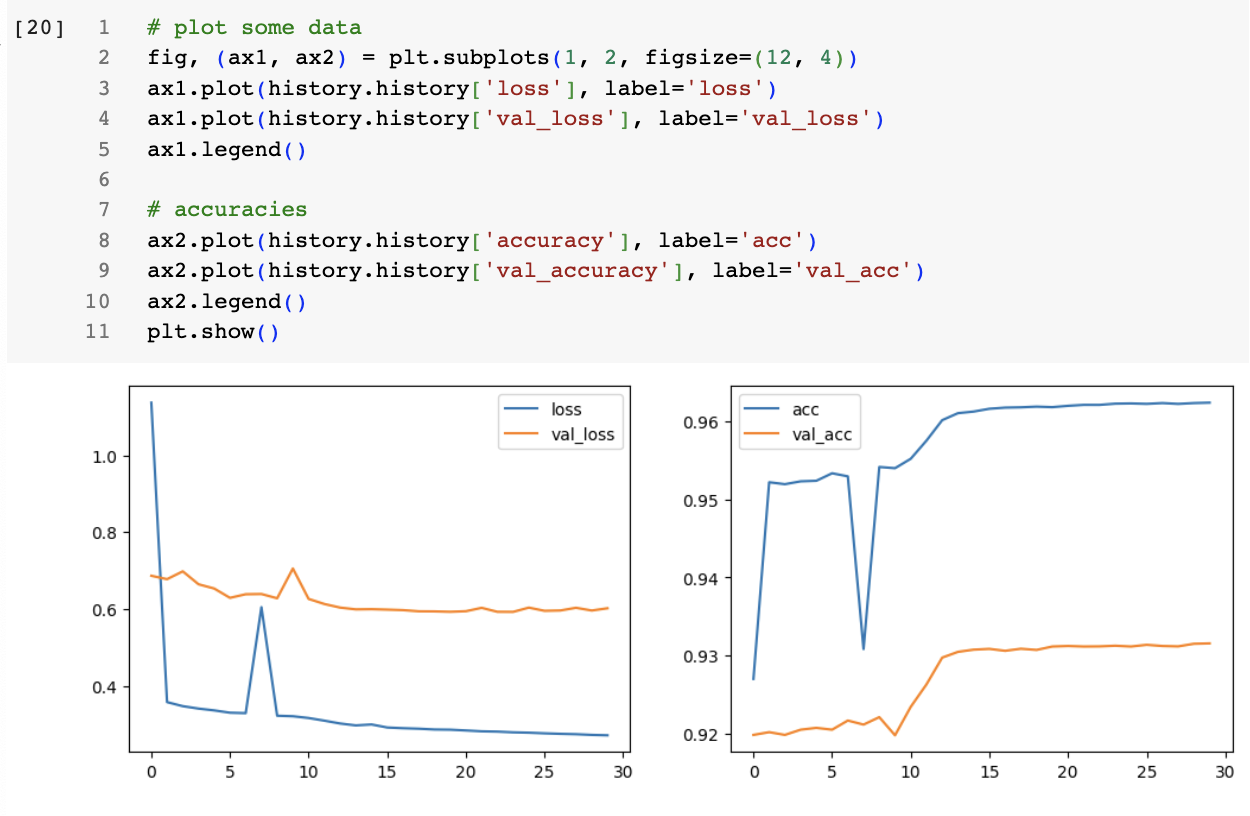
 이 것이 교재에 포함되어 있던 loss/val_loss 와 acc/val_acc 플롯인데 위에 첨부하신 플롯과 크게 차이가 없습니다.
이 것이 교재에 포함되어 있던 loss/val_loss 와 acc/val_acc 플롯인데 위에 첨부하신 플롯과 크게 차이가 없습니다.
 둘다 loss 는 줄어드는데 val-Loss 는 별로 줄어들지 않는 전형적인 overfitting의 모습을 보이고 있습니다.
둘다 loss 는 줄어드는데 val-Loss 는 별로 줄어들지 않는 전형적인 overfitting의 모습을 보이고 있습니다.
이러한 현상은 딥러닝 모델의 학습 데이터가 충분하지 않을 때 흔히 볼 수 있는 현상입니다.
조금 더 진도를 나가시면 이러한 RNN 을 이용한 딥러닝 언어 모델의 문제점이 어떻게 해결되었는지 이해하실 수 있습니다. 즉, Transformer 를 이용해 딥러닝 모델 사이즈의 확장과 대용량의 데이터를 이용한 overfitting 문제 해결을 하게 되었고 요즘 핫 이슈가 되고 있는 ChatGPT 같은 LLM (Large Language Model)의 탄생 배경이 되게 되었습니다. 문제는 Transformer 를 이용한 대형 언어 모델은 어차피 우리가 직접 만들 수 없는 size 이고 데이터 용량도 강의 교재로 사용 불가능한 크기 입니다. 다만 그 원리를 이해하기 위해 Colab 이나 local PC 에서 실행 가능한 크기의 RNN을 이용한 encoder-decoder 모델을 만든 것 이므로 딥러닝 언어 모델의 성능을 크게 기대하지는 마시고 혹시 교재에서와 같이 그럴 듯한 대화나 번역이 되기를 원하신다면 가능한 Training data 에 포함된 문장과 비슷한 문장을 입력하시기 바랍니다. 저도 그럴듯하게 보이는 교재를 만들기 위해 https://github.com/ironmanciti/NLP_lecture/raw/master/data/kor.txt 데이터 내용을 들여다 보고 비슷한 문장을 입력하였습니다. 어차피 Transformer의 작동 원리를 이해하기 위한 과정이므로 성능 보다는 원리 파악에 중점을 두시기 바랍니다.
좋은질문 감사합니다.