인프런 커뮤니티 질문&답변
작성한 질문수

범주형변수를 포함한 다중선형회귀 모델에서 독립변수 사용 방식
해결된 질문
작성
·
622
·
수정됨
0
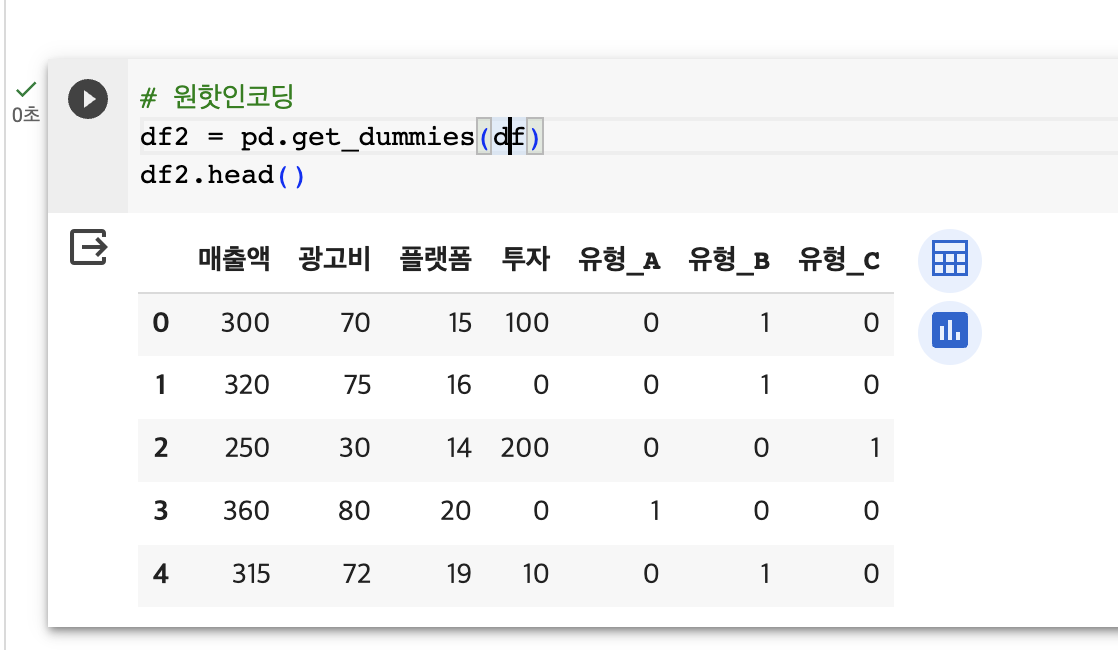
 강의 중 ols함수를
강의 중 ols함수를
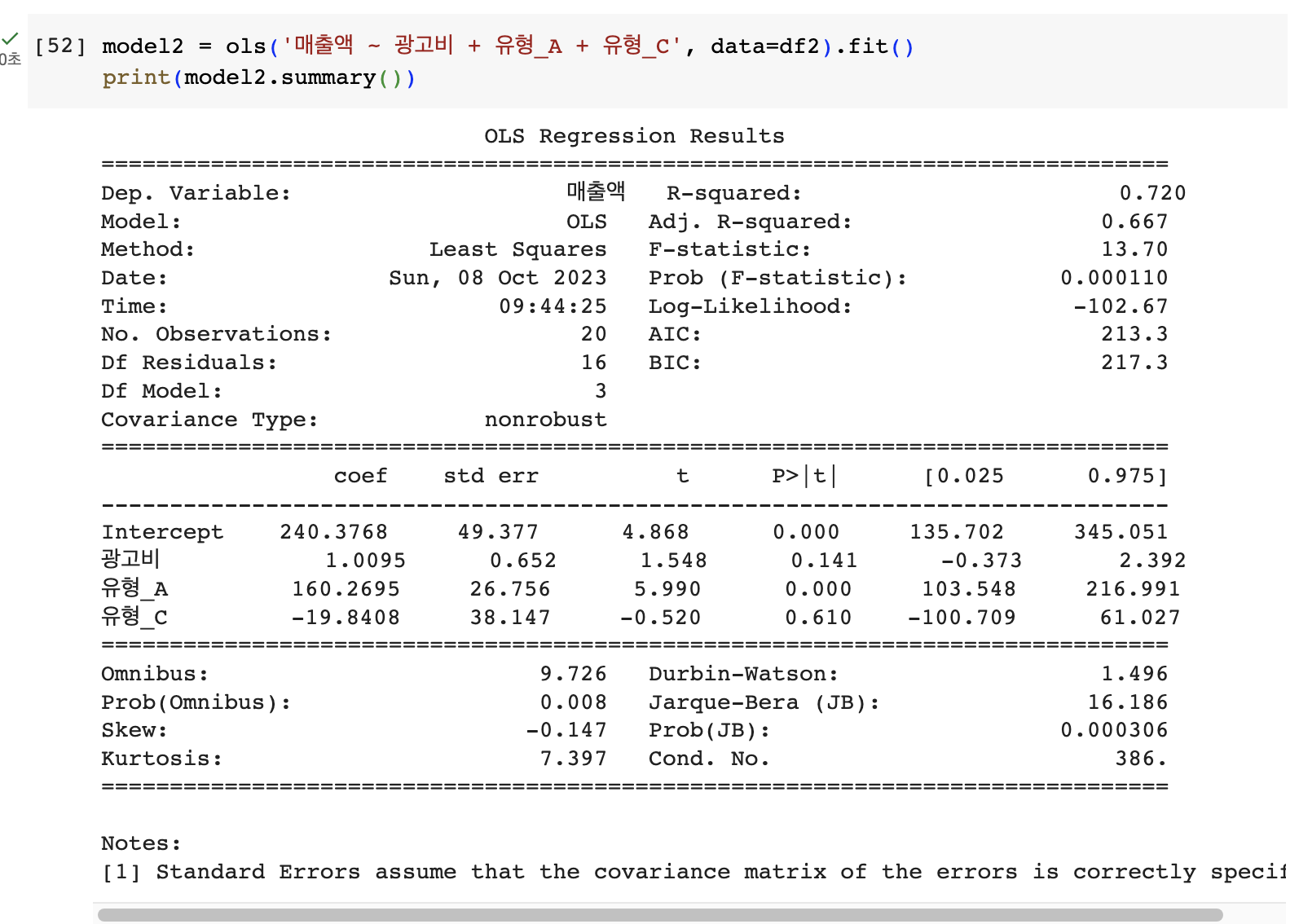
ols('매출액 ~ 광고비 + 유형_A + 유형_C', data=df2).fit()
이런식으로 범주형 변수의 일부 컬럼만 사용해서 회귀모델을 구축할 수 있다고 하셨습니다.그래서 테스트를 해 본 결과 위와 같이 유형_A와 유형_C를 회귀모델의 독립변수로 활용하기 위해서는
df = pd.get_dummies(df, drop_first=True)이런식으로 다중공선성 방지를 위한 파라미터를 추가하는게 아니라 위 캡처본에서의 df2와 같이 전체 변수가 포함된 데이터프레임을(유형_A, 유형_B, 유형_C 가 전부 포함된 데이터프레임) 사용해야 하는 것을 알았습니다.
근데, 이렇게 df2와 유형_A, 유형_C를 활용한 회귀모델은 유형_B를 감안한 것이 아니라 그냥 유형_B만 갑자기 누락해버린 회귀모델이 아닐지 문의드립니다.
import pandas as pd
df = pd.DataFrame({
'매출액' : [300, 320, 250, 360, 315, 328, 310, 335, 326, 280, 290, 300, 315, 328, 310, 335, 300, 400, 500, 600]
, '광고비': [70, 75, 30, 80, 72, 77, 70, 82, 70, 80, 68, 90, 72, 77, 70, 82, 40, 20, 75, 80]
, '플랫폼': [15, 16, 14, 20, 19, 17, 16, 19, 15, 20, 14, 5, 16, 17, 16, 14, 30, 40, 10, 50]
, '투자':[100, 0, 200, 0, 10, 0, 5, 0, 20, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
, '유형':['B','B','C','A','B','B','B','B','B','B' ,'C','B','B','B','B','B','B','A','A','A']
})
df = pd.get_dummies(df, drop_first=True)
from statsmodels.formula.api import ols model = ols('매출액 ~ 광고비 + 유형_B + 유형_C', data=df).fit()
print(model.summary())
위에서는 엄연히 유형_A도 감안된 것일텐데 이런 상황에서 유형_A를 회귀모델 독립변수로 쓰지 않은 것과는 (매출액 ~ 광고비 + 유형_B + 유형_C) 다른 결인 것 같아서요!
답변 1
0
매출액 ~ 광고비 + 유형_B + 유형_C에서 유형A를 변수로는 사용하지 않았습니다. B와 A의 범주값을 알면 C를 알 수 있어요! "없으니 사용하지 않는 것 아닌가요?" 라고 생각할 수 있는데 사용하지 않은 것은 아닙니다. 원핫 인코딩의 방법이 다를 뿐 사용하고 있습니다. 유형B와 유형C에 대한 회귀계수는 유형A의 상대적인 효과를 나타냅니다.
ols('매출액 ~ 광고비 + 유형', data=df).fit()과 원핫인코딩 후 ols('매출액 ~ 광고비 + 유형_B + 유형_C', data=df).fit()의 summary()결과는 같습니다.
따라서 문제를 정말 어렵게 출제하지 않는 이상 기준(참조 범수)는 일반적으로는 첫 번째 컬럼을 제거한(참조변수로 사용한) 원핫인코딩한 결과값(model.summary())중에 회귀계수, 결정계수, p-value값을 묻지 않을까 싶어요!
더불어 항상 제가 미처 고려하지 못한 좋은 질문주셔서 감사합니다. 추가적으로 궁금한 점이 있다면 댓글 달아주세요!💪